Scrapy作为一个非常好用的数据爬取框架,以前看过它的一些视频。最近找到了一个电子书的网站, http://mebook.cc/ , 网站内容做的不错,就是布局上每页只有10本书 ,导致分页太多,一页一页翻过去找太麻烦了,心想何不自己写个爬虫来爬一下。粗看了一些它的网页结构,用Wordpress搭建的,网页非常规整,比较容易爬取,于是说干就干,翻开Scrapy的官网教程,实现了爬取并保存书目和下载地址。以下简单总结爬取过程中的体会。
下载安装Scrapy 和Beautifulsoup4
我的爬虫项目里用到了Scrapy和bs4这两个包。安装它们很简单,在PyCharm里创建个新项目(可以使用虚拟环境),然后pip install scrapy和bs4就好了。另外windows环境下还需要安装pip install pywin32,否则scrapy执行时会报错。bs4是一个HTML/XML 分析工具,可以很方便提取出页面内的各种元素。
创建Scrapy项目
在Pycharm的Terminal里输入 scrapy createproject prjName即可。按照教程说明,在spider包里添加自己的爬虫实现文件即可。
原网站每页只显示最多10本,而spider是异步并发的,发出请求后就立即返回。对于我的实例,每个分页的链接只有末尾的数字不同, http://mebook.cc/category/xx/page/n
所以scrapy并发出多个顺序请求后,返回的结果并不是顺序返回,因此返回代码里先把所有返回结果缓存一下,排序后再保存到文件,这样就可以保持原有页面顺序。很感谢网站开发者的分享,但如果能提供个目录索引页就会方便很多了,也就不用我再辛苦去编程爬取了。
几个有用的尝试
1. PyCharm里添加Scrapy调试支持
scrapy项目默认是不支持断点调试的,运行需要使用 scrapy crawl spiderName的方式。而在开发过程中,断点调试还是非常好用的,因此搜索了一下网络,参照 https://blog.csdn.net/u012052268/article/details/72063917 实现了Pycharm里对Scrapy项目的调试支持。
具体做法就是额外创建一个python脚本文件main.py,内容如下,其中books是我的爬虫的名字:
from scrapy import cmdline
cmdline.execute("scrapy crawl books".split())
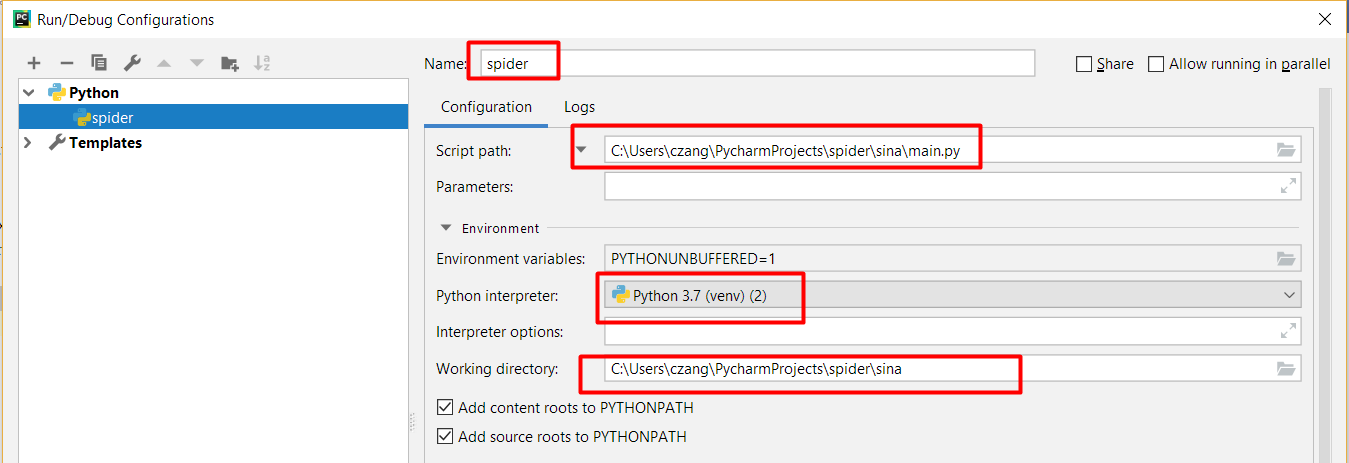
将上述文件放到爬虫项目目录下(和scrapy.cfg文件同级),然后在PyCharm里的Run ->Edit configuration里添加一个可运行的Python模块就可以了,如下图。名字任意填,脚本路径和工作目录选对即可。调试的时候要点击绿色虫子图标就可以开始调试了。
2.PyCharm里shell交互式调试
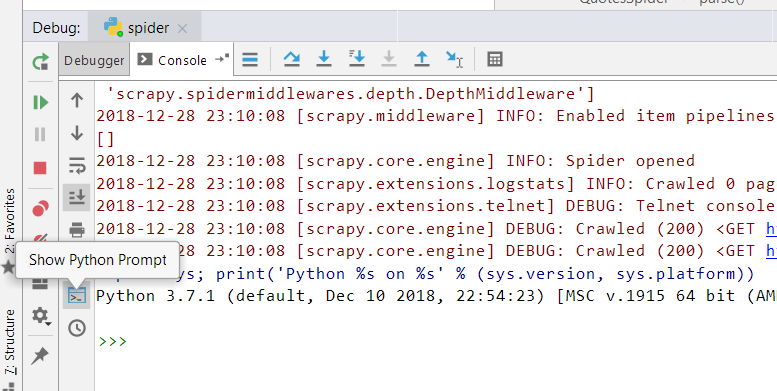
通过上面配置就可以实现断点调试,当程序运行到断点处,就可以使用python shell来进行交互了。PyCharm里这点在界面上做得不是很明显。需要先点击Console tab,然后再点击左下角的Show Python Prompt图标才会出现此交互shell。出现后就可以在shell里执行各种调试命令了,比如打印出某个变量的值,对某个变量进行一些操作等,这点和Matlab的交互式调试非常像。
3. Unicode 问题
开发过程中,因为书目都是用中文写的,而且有些外国作者名字的First Name和Last Name之间用了个奇怪的点号(不是句号),结果在print和保存到文件的时候就不断报错:UnicodeEncodeError: 'gbk' codec can't encode character: illegal multibyte sequence。上网搜了一下,解决办法比较简单,创建保存文件的时候,加入一个参数encoding='utf-8',
fwriteLog = open(self.logfilename, 'w', encoding='utf-8')
根源是因为Windows创建一个文本文件时不是使用默认的utf-8。至于print函数,也有类似解决办法,因为我不使用,所以没有细究。
几点有用信息
1.彻底理解Python中的yield:https://www.jianshu.com/p/d09778f4e055
2. 有些网页没有使用utf-8,而是使用gb232等,可以在scrapy的parse函数里做如下修改即可,先用gb18030解码后再用utf-8编码,因为后续的bs4里都是用unicode编码:

3. 从汉字数字混合字符串里提取出所有数字:数字的形式无非是 [-]n[.][m]的形式,因此采用re进行查找,利用如下规则:
\d 表示 [0-9]的任一个数字;
\.用来匹配小数点符号,不加斜杠就代表匹配除了newline符号外的任意符号;
? 它前面的符号要出现 0或1次,因此我们用来查找负号-和小数点;
+ 表示它前面的符号要出现1到多次,用来查找整数部分;
* 表示它前面的符号要出现0到多次,用来查找小数部分 ;
函数语法是 re.find_all(patten, str) ,因此我们可以运行如下:
re.findall('-?\d+.?\d*', '共200条数据 页次:123/456页,值是-6.789)')
['200', '123', '456', '-6.789']